 El código ASCII (acrónimo inglés de American Standard Code for Information Interchange — (Código Estadounidense Estándar para el Intercambio de Información), pronunciado generalmente [áski], es un código de caracteres basado en el alfabeto latino tal como se usa en inglés moderno y en otras lenguas occidentales. Fue creado en 1963 por el Comité Estadounidense de Estándares (ASA, conocido desde 1969 como el Instituto Estadounidense de Estándares Nacionales, o ANSI) como una refundición o evolución de los conjuntos de códigos utilizados entonces en telegrafía. Más tarde, en 1967, se incluyeron las minúsculas, y se redefinieron algunos códigos de control para formar el código conocido como US-ASCII.
El código ASCII (acrónimo inglés de American Standard Code for Information Interchange — (Código Estadounidense Estándar para el Intercambio de Información), pronunciado generalmente [áski], es un código de caracteres basado en el alfabeto latino tal como se usa en inglés moderno y en otras lenguas occidentales. Fue creado en 1963 por el Comité Estadounidense de Estándares (ASA, conocido desde 1969 como el Instituto Estadounidense de Estándares Nacionales, o ANSI) como una refundición o evolución de los conjuntos de códigos utilizados entonces en telegrafía. Más tarde, en 1967, se incluyeron las minúsculas, y se redefinieron algunos códigos de control para formar el código conocido como US-ASCII.ASCII fue publicado como estándar por primera vez en 1967 y fue actualizado por última vez en 1986. En la actualidad define códigos para 33 caracteres no imprimibles, de los cuales la mayoría son caracteres de control obsoletos que tienen efecto sobre como se procesa el texto, más otros 95 caracteres imprimibles que les siguen en la numeración (empezando por el carácter espacio).
Historia
Yezla Dayana y Mariana dicen que El código ASCII se desarrolló en el ámbito de la telegrafía y se usó por primera vez comercialmente como un código de teleimpresión impulsado por los servicios de datos de Bell. Bell había planeado usar un código de seis bits, derivado de Fieldata, que añadía puntuación y letras minúsculas al más antiguo código de teleimpresión Baudot, pero se les convenció para que se unieran al subcomité de la Agencia de Estándares Estadounidense (ASA), que habían empezado a desarrollar el código ASCII. Baudot ayudó en la automatización del envío y recepción de mensajes telegráficos, y tomó muchas características del código Morse; sin embargo, a diferencia del código Morse, Baudot usó códigos de longitud constante. Comparado con los primeros códigos telegráficos, el código propuesto por Bell y ASA resultó en una reorganización más conveniente para ordenar listas (especialmente porque estaba ordenado alfabéticamente) y añadió características como la 'secuencia de escape'.
Los caracteres de control ASCII
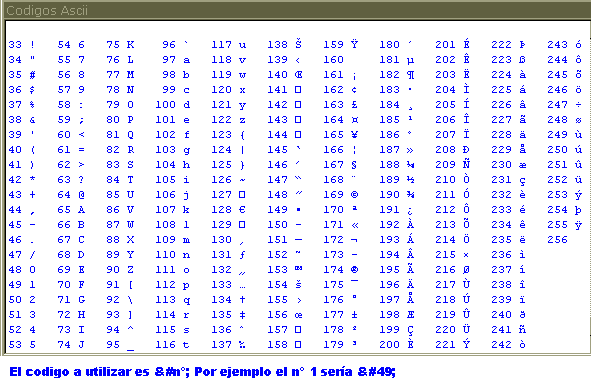
El código ASCII reserva los primeros 32 códigos (numerados del 0 al 31 en decimal) para caracteres de control: códigos no pensados originalmente para representar información imprimible, sino para controlar dispositivos (como impresoras) que usaban ASCII. Por ejemplo, el carácter 10 representa la función "nueva línea" (line feed), que hace que una impresora avance el papel, y el carácter 27 representa la tecla "escape" que a menudo se encuentra en la esquina superior izquierda de los teclados comunes.
Caracteres imprimibles ASCII
El código del carácter espacio, designa al espacio entre palabras, y se produce normalmente por la barra espaciadora de un teclado. Los códigos del 33 al 126 se conocen como caracteres imprimibles, y representan letras, dígitos, signos de puntuación y varios símbolos.
El ASCII de siete bits proporciona siete caracteres "nacionales" y, si la combinación concreta de hardware y software lo permite, puede utilizar combinaciones de teclas para simular otros caracteres internacionales: en estos casos un backspace puede preceder a un acento abierto o grave (en los estándares británico y americano, pero sólo en estos estándares, se llama también "opening single quotation mark"), una tilde o una "marca de respiración".
Rasgos estructurales
Los dígitos del 0 al 9 se representan con sus valores prefijados con el valor 0011 en binario (esto significa que la conversión BCD-ASCII es una simple cuestión de tomar cada unidad bcd y prefijarla con 0011).
Las cadenas de bits de las letras minúsculas y mayúsculas sólo difieren en un bit, simplificando de esta forma la conversión de uno a otro grupo.
Vista general
Las computadoras solamente entienden números. El código ASCII es una representación numérica de un carácter como ‘a’ o ‘@’.[1]
Como otros códigos de formato de representación de caracteres, el ASCII es un método para una correspondencia entre cadenas de bits y una serie de símbolos (alfanuméricos y otros), permitiendo de esta forma la comunicación entre dispositivos digitales así como su procesado y almacenamiento. El código de caracteres ASCII[2] — o una extensión compatible (ver más abajo) se usa casi en todos los ordenadores, especialmente con ordenadores personales y estaciones de trabajo. El nombre más apropiado para este código de caracteres es "US-ASCII".






{kind=link}